
![]()
Por Luis Navas
Un enfoque para disminuir la degradación del sistema de control y las paradas no programadas de planta
El ingeniero electrónico Luis Alberto Navas es Ingeniero Senior de Control de Procesos en Bayer Argentina – Crop Services y cuenta con certificación CAP (Certified Automation Professional) de parte de ISA. Cuenta con más de trece años de experiencia en automatización de procesos en diferentes industrias, y participó de la ejecución de diversos proyectos en Latinoamérica
El diagnóstico de los sistemas de control es frecuentemente una herramienta subutilizada y, en el peor de los casos, ni siquiera usada. Pero así como un paciente va al médico y realiza exámenes de diagnóstico para controlar su salud, lo mismo debería ocurrir con los sistemas de control industrial. Esto se puede realizar mediante el monitoreo de las alarmas que por defecto tienen disponibles los equipos o sobre alarmas personalizadas, evitando así una degradación progresiva del sistema de control, la cual podría terminar en una parada de planta no deseada.
Nadie quisiera escuchar: "La planta se ha detenido por una falla en el sistema de control". Y justamente el objetivo es evitar que suceda eso o, al menos, reducir la probabilidad de que ocurra, haciendo un uso eficiente de las capacidades de diagnóstico disponibles.
Para cualquier problema en la vida, sea técnico o no, hay que tratar de entender la problemática de la manera más objetiva posible, después analizarla y generar un plan. Posteriormente,se ha de implementar, verificando los resultados y tomando acciones correctivas si hiciese falta. Como consecuencia, se plantean los siguientes puntos para desarrollar:
+ Problemática actual
+ Análisis
+ Implementación
+ Resultados 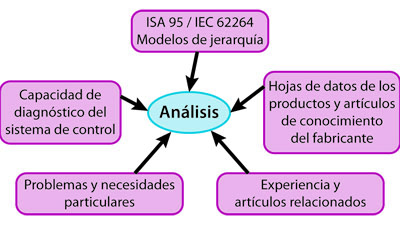 Figura 1. Entradas para análisis del diagnóstico de su sistema de control
Figura 1. Entradas para análisis del diagnóstico de su sistema de control
Problemática actual
Como una aproximación al entendimiento de la situación actual, en cuanto al uso y gestión del diagnóstico de los sistemas de control, se plantean los siguientes interrogantes:
+ ¿Se conocen las alarmas disponibles del sistema de control?
+ ¿Son atendidas las alarmas del sistema de control cuando estas se activan?
+ ¿El mantenimiento del sistema de control es preventivo o reactivo?
+ ¿Son usadas todas las capacidades de diagnóstico del sistema?
+ ¿La planta se ha detenido por fallas en el sistema de control?
+ Cuando ocurre una falla, ¿es claro qué hacer?, ¿dónde buscar?, ¿qué herramientas usar?
+ ¿Los tiempos de resolución de fallas, usualmente, son largos o cortos?
Reflexionando sobre las respuestas a los interrogantes anteriores, dependiendo del tipo de industria, los regímenes de producción y las particularidades de cada planta, se puede vislumbrar el estadio actual en cuanto al uso del diagnóstico y capacidad de respuesta ante alarmas y fallos.
Análisis
Para realizar el análisis, se proponen las entradas mostradas en la figura número 1.
La ISA 95/IEC 62264 provee el marco (framework) sobre el cual se aplicaría el sistema de diagnóstico, específicamente sobre el modelo jerárquico de los procesos industriales, también conocido como la “pirámide de la automatización”.
La capacidad de diagnóstico del sistema se refiere a aquellas herramientas que provee el fabricante, bien sea de software o hardware, para el diagnóstico de sus equipos y de uso disponible para el usuario final; ejemplo de ello son los indicadores luminosos tipo led, códigos de error, bytes de estado, estado de conexión de red, uso de CPU, memoria libre, espacio de disco libre, error en algoritmos, temperatura interna o error en entradas/salidas, entre otros.
Las hojas de datos de los productos suministran información útil relacionada con los límites máximos y mínimos como temperatura, vibración, humedad relativa y tensión de alimentación. Por otra parte, brindan especificaciones técnicas propias del equipo como cantidad de memoria de usuario disponible, capacidad de CPU, y otros específicos de cada fabricante. Todos estos valores ayudan a definir umbrales de alarmas en el sistema de diagnóstico. Adicionalmente los artículos de conocimiento aportan al análisis, pues aclaran la interpretación de los parámetros de diagnóstico y también proveen información que posibilita un entendimiento más profundo del equipo.
Es deseable contar con la experiencia de trabajo en sistemas de automatización y haber afrontado multitud de fallas, pues ayuda a definir un norte a los esfuerzos de diagnóstico del sistema y provee elementos de juicio para una correcta toma de decisiones. Ahora bien, cuando no se tiene dicha experiencia, es conveniente basar las decisiones en artículos, whitepapers de fabricantes, usuarios finales y organizaciones de estandarización locales y/o internacionales.
Finalmente,se propone reflexionar sobre los problemas locales y las necesidades. Así como abordar las soluciones con eficacia, eficiencia, evitando perder tiempo y buscando sustentabilidad a largo plazo.
Como resultado de dicho análisis se propone el siguiente diagrama de la figura 2, con los elementos/equipos que serán revisados. 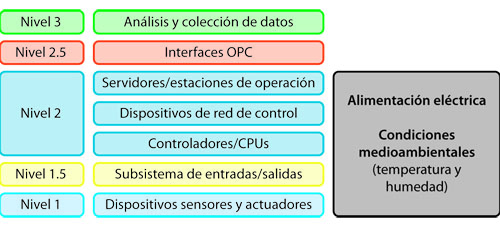 Figura 2. Elementos que serán diagnosticados, en el marco del modelo de jerarquía funcional de la ISA 95
Figura 2. Elementos que serán diagnosticados, en el marco del modelo de jerarquía funcional de la ISA 95
Implementación
Una vez realizado el análisis y habiendo definido los equipos que se analizarán, el siguiente paso es la implementación. A continuación, algunas premisas y pasos para realizar:
1. Para los dispositivos de cada nivel,es necesario verificar las capacidades de diagnóstico de cada uno, la documentación del fabricante, los valores límite para generar alarmas, y documentación relacionada como se sugirió en la etapa de análisis.
2. En planta debe existir, al menos, un responsable del mantenimiento del sistema de control, de su diagnóstico y de la respuesta a las alarmas y eventos que surjan.
3. Verificar que estén habilitadas las alarmas que vienen por defecto en los diferentes dispositivos y equipos.
4. De ser necesario,generar alarmas personalizadas, pues es una buena estrategia generar alarmas “inteligentes” que vinculen las alarmas individuales de acuerdo con la arquitectura existente.
5. Todas las alarmas que generan por defecto los dispositivos y aquellas que se creen de manera personalizada deben ser segregadas del resto de las alarmas del proceso, pues hay que tener en
claro que sería imposible atender, de manera oportuna, alguna alarma del sistema de control siesta se confunde con otro tipo de alarmas.
6. Si la planta es mediana o grande,es recomendable segregar las alarmas por área, para poder tener una respuesta más efectiva.
7. Generar objetos gráficos en el HMI disponible, que representen gráficamente los equipos y sus interconexiones, de tal manera que quede representada la arquitectura del sistema.
8. Agregar atributos de alarmado, valores numéricos y animaciones que sean relevantes para la visualización y escucha. Este punto en conjunto con el anterior dan como resultado una herramienta valiosa, pues en un vistazo y resumidamente se observará el estado del sistema. Un ejemplo de ello es la figura número 3.
9. Considerar al menos una estación de mantenimiento desde la cual sea posible monitorear, diagnosticar y atender las alarmas.
10. Si la cantidad de alarmas es abrumadora (miles a millones), se sugiere exportar las alarmas a alguna hoja de cálculo o software de business intelligence, con el objeto de identificar las alarmas ruidosas, (nuisance alarms), e ir eliminándolas, lo cual disminuirá drásticamente la cantidad de alarmas.
11. Involucrar al personal de mantenimiento, al plantel técnico, al operativo y transferir el concepto y la utilidad de la herramienta, ya que una falla puede ocurrir un domingo a la madrugada y una respuesta rápida es vital.
A continuación, se sugieren algunas líneas como ejemplo de diagnóstico para cada nivel.
Nivel 1
+ Hacer uso de la instrumentación (sensores y actuadores) con capacidad de diagnóstico y alarmado propio, o también llamada instrumentación “inteligente”.
+ Capturar dichas alarmas a través del sistema de control o de algún sistema de gestión de instrumentación.
+ Posteriormente, actuar sobre dichas alarmas de manera oportuna.
+ Ejemplos típicos de dichas alarmas pueden ser “sensor en falla”, “alerta por desviación”, “bajo suministro de aire” o “alarma de mantenimiento”, entre otros.
Nivel 1.5
+ Verificar los subsistemas y sistemas I/O, leer sus especificaciones.
+ Aprovechar el diagnóstico disponible y sus alarmas y, según sea el caso, generar alarmas personalizadas.
+ Para este nivel, a parte del I/O convencional, aplican también buses de campo como ProfiBus DP, ProfiBus PA, Foundation Fieldbus, Device-Net, ASI-Bus, Modbus TCP/RTU/ASCII, Ethernet Industrial o cualquier protocolo de comunicación.
+ Es pertinente hacer uso del diagnóstico disponible y el uso de watchdogs en las comunicaciones.
Nivel 2
+ Al igual que el punto anterior, verificar toda la documentación y capacidades de diagnóstico de controladores/CPU, dispositivos de red, estaciones de operación, servidores.
+ Algunos ejemplos pueden ser: espacio de disco, porcentaje libre de CPU, RAM, temperatura interna, conexión de red, entre otros.
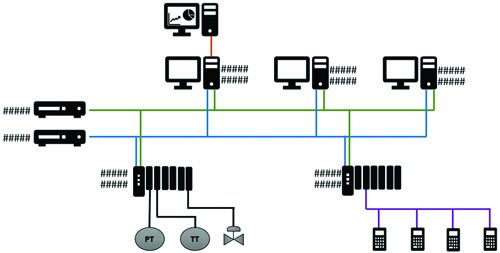 Figura 3. Arquitectura de un sistema de control a modo de ejemplo para diagnóstico en pantalla de HMI Nivel 1 a 2
Figura 3. Arquitectura de un sistema de control a modo de ejemplo para diagnóstico en pantalla de HMI Nivel 1 a 2
+ Monitorearla alimentación eléctrica, tomando información de las UPS, idealmente a través de un cable de red vía SNMP/Modbus TCP, u otro protocolo de comunicación disponible.
+ Monitorear la temperatura y humedad en los lugares críticos como la sala de racks y, en general, donde estén ubicados los dispositivos electrónicos.
+ Una muy alta humedad favorece la corrosión y una muy baja, el flujo de corrientes estáticas; ambas afectan los equipos electrónicos.
+ Una muy baja temperatura afecta el valor resistivo de los conductores y resistencias, y una muy alta degrada drásticamente los equipos.
+ El tiempo promedio entre fallas (MTBF) calculado por el fabricante está basado en una temperatura de veinticinco grados centígrados (25°C); con lo cual si la temperatura aumenta, acelera progresivamente el factor de envejecimiento de la electrónica, y esto a su vez reduce el MTBF (MIL-HDBK-217).
Nivel 2.5
+ Si existen vínculos entre el sistema de control y algún software de históricos, o de gestión como, por ejemplo, MES, OEE, entre otros, se debe usar aquella información que se tenga disponible para verificar que la conexión está funcionando correctamente.
+ Es recomendable implementar watchdogs y generar alarmas.
Nivel 3
+ Explorar cada aplicación en particular.
+ Indagar con el especialista si es aplicable o no un diagnóstico desde el sistema de control, o sobre cómo contribuir para que se tenga mejor diagnóstico desde la aplicación.
Resultados
Un buen uso y aprovechamiento del diagnóstico del sistema trae como consecuencia los siguientes resultados (tangibles e intangibles):
+ Detección temprana de fallas
+ Mejor tiempo de identificación de fallas
+ Visualización de la salud del sistema en un vistazo
+ Disminución de la degradación del sistema de control
+ Mejora en la confiabilidad y disponibilidad del sistema de control
+ Disminución de paradas potenciales de planta
+ Mayor certeza sobre dónde enfocar los esfuerzos
+ Incremento en la confianza del sistema por el mantenedor y por parte de otras áreas
+ Mayor tranquilidad
Resumen y conclusiones
+ El diagnóstico disponible de los equipos que conforman un sistema de control es poco usado.
+ Se puede implementar un sistema de diagnóstico útil, realizando un buen análisis de las problemáticas, oportunidades y recursos disponibles.
+ Con el análisis de las alarmas del sistema es posible identificar los puntos críticos y tener mayor certeza sobre dónde enfocar los esfuerzos del mantenedor.
+ Un sistema de diagnóstico bien implementado trae consigo numerosas ventajas, tangibles e intangibles para la planta.