
“Nube” es un término que se utiliza de diferentes formas y, a menudo, mantiene un significado abstracto que no se explica mucho. Normalmente, solo se logra una idea clara cuando se leen las ofertas de los proveedores de servicios en la nube y se prueban los servicios disponibles.
Primeros pasos en la nube
“Nube” es un término que se utiliza de diferentes formas y, a menudo, mantiene un significado abstracto que no se explica mucho. Normalmente, solo se logra una idea clara cuando se leen las ofertas de los proveedores de servicios en la nube y se prueban los servicios disponibles. Para nuestra sorpresa, estos primeros pasos son bastante simples. Las cuentas de prueba se crean online rápidamente y permanecen activas por un periodo de tiempo limitado o con una propuesta de funciones restringida. Esto brinda una idea de los posibles servicios que se pueden obtener por un importe determinado (ver figura 1).
“Nube” es un término que se utiliza de diferentes formas y, a menudo, mantiene un significado abstracto que no se explica mucho
La cantidad de servicios crece rápidamente y es fácil perderles el rastro. Según la industria o su uso, a menudo al cliente solo le interesa realmente una parte de estos servicios.
En general, cada servicio individual tiene, a su vez, un modelo de cotización variable que depende de su configuración.
Si la tarea específica es mover datos de la red de automatización a la nube para analizar o visualizar los datos ahí, entonces, los servicios principales que se necesitan son los de la categoría IoT. El primer paso es crear un servicio de interfaz y configurar los puntos de acceso en esta interfaz que utilizarán los dispositivos de campo.
En la mayoría de los casos, se instancia el broker MQTT y se crean los dispositivos y usuarios que pueden publicar ahí. El broker se aloja en un centro de datos (seleccionable) del proveedor de la nube al que se accede con una URL personalizada. El costo de este servicio normalmente depende de la cantidad de mensajes que se pueden enviar (los dispositivos de campo) al broker en un periodo determinado. Por ejemplo: 5000 mensajes por día a una tarifa mensual de 4,99 euros (en Europa). De este modo, las terminales con capacidad MQTT pueden transmitir y buscar datos de este broker.
En general, cada servicio individual tiene, a su vez, un modelo de cotización variable que depende de su configuración.
Si la tarea específica es mover datos de la red de automatización a la nube para analizar o visualizar los datos ahí, entonces, los servicios principales que se necesitan son los de la categoría IoT. El primer paso es crear un servicio de interfaz y configurar los puntos de acceso en esta interfaz que utilizarán los dispositivos de campo.
En la mayoría de los casos, se instancia el broker MQTT y se crean los dispositivos y usuarios que pueden publicar ahí. El broker se aloja en un centro de datos (seleccionable) del proveedor de la nube al que se accede con una URL personalizada. El costo de este servicio normalmente depende de la cantidad de mensajes que se pueden enviar (los dispositivos de campo) al broker en un periodo determinado. Por ejemplo: 5000 mensajes por día a una tarifa mensual de 4,99 euros (en Europa). De este modo, las terminales con capacidad MQTT pueden transmitir y buscar datos de este broker.
La implementación de la aplicación real en la nube es solo el inicio. Luego, se pueden solicitar servicios que analicen, filtren o muestren los datos del broker
La implementación de la aplicación real en la nube es solo el inicio. Luego, se pueden solicitar servicios que analicen, filtren o muestren los datos del broker (y, por ende, de los dispositivos de campo). Por ejemplo, el servicio de análisis de datos puede evaluar los datos del broker y filtrarlos según valores específicos. A su vez, este resultado se puede enviar a una visualización ejecutada en un servidor web (alojado por el proveedor de servicios en la nube). Por lo tanto, el estado de la planta se puede poner a disposición del técnico de servicio en cualquier momento sin tener que establecer una infraestructura propia.
Sin embargo, también podemos ver que incluso en este caso de ejemplo se requiere la interacción compleja de, al menos, cinco servicios de un proveedor en la nube (broker MQTT, análisis de datos, visualización, almacenamiento y servidor web).
Como la conexión de los dispositivos de automatización a un broker MQTT tiene un rol fundamental, la implementación de aplicaciones industriales en la nube requiere un conocimiento minucioso del protocolo MQTT.
Sin embargo, también podemos ver que incluso en este caso de ejemplo se requiere la interacción compleja de, al menos, cinco servicios de un proveedor en la nube (broker MQTT, análisis de datos, visualización, almacenamiento y servidor web).
Como la conexión de los dispositivos de automatización a un broker MQTT tiene un rol fundamental, la implementación de aplicaciones industriales en la nube requiere un conocimiento minucioso del protocolo MQTT.
Como la conexión de los dispositivos de automatización a un broker MQTT tiene un rol fundamental, la implementación de aplicaciones industriales en la nube requiere un conocimiento minucioso del protocolo MQTT
Breviario de MQTT
MQTT son las siglas en inglés de “Transporte de telemetría de cola de mensajes” (‘Message Queuing Telemetry Transport’) y es un protocolo de comunicación que concibieron originalmente los empleados de IBM en 1999 para intercambiar datos de la forma más eficiente posible a través de redes inestables y de bajo rendimiento. No obstante, en los últimos años, el protocolo se abrió camino exitosamente hacia las aplicaciones de IoT, desplazando al resto de los protocolos. En la actualidad, su especificación la está refinando la Organización para el Avance de los Estándares de la Información Estructurada (OASIS, por sus siglas en inglés) y está disponible sin cargo.
En los últimos años, el protocolo [MQTT] se abrió camino exitosamente hacia las aplicaciones de IoT, desplazando al resto de los protocolos
El protocolo MQTT funciona según el principio publicación-suscripción (pub/sub) para el intercambio de datos entre una cierta cantidad de participantes. Hay una instancia central, el llamado “broker”, que administra y distribuye todos los datos en circulación. Un participante que desea compartir información lo hace cuando publica sus datos en el broker. Un participante interesado en datos se puede suscribir al broker y recibirá de este los datos que le interesen. En la teoría, cualquier cantidad de dispositivos se pueden registrar con el broker para editar y suscribir. Asimismo, un participante puede ser editor y suscriptor a la vez.
La mayor ventaja es que no se necesitan conexiones punto a punto, por lo tanto, se puede desvincular a participantes de forma positiva y reducir la complejidad. Este concepto ofrece nuevas libertades que principalmente tienen los siguientes efectos:
Independencia de los participantes. Un emisor de datos (editor) no conoce a los destinatarios finales (suscriptores), y viceversa. Por ende, las direcciones clásicas de los participantes y su administración no se aplican en este nivel.
Independencia temporal. La emisión y recepción de datos puede ocurrir en cualquier momento y, por sobre todo, en diferentes horarios. Al editor le resulta indistinto si sus suscriptores están interesados en los datos en ese momento o si actualmente están apagados y, por ende, los utilizarán más tarde.
La mayor ventaja es que no se necesitan conexiones punto a punto, por lo tanto, se puede desvincular a participantes de forma positiva y reducir la complejidad. Este concepto ofrece nuevas libertades que principalmente tienen los siguientes efectos:
Independencia de los participantes. Un emisor de datos (editor) no conoce a los destinatarios finales (suscriptores), y viceversa. Por ende, las direcciones clásicas de los participantes y su administración no se aplican en este nivel.
Independencia temporal. La emisión y recepción de datos puede ocurrir en cualquier momento y, por sobre todo, en diferentes horarios. Al editor le resulta indistinto si sus suscriptores están interesados en los datos en ese momento o si actualmente están apagados y, por ende, los utilizarán más tarde.
La mayor ventaja es que no se necesitan conexiones punto a punto, por lo tanto, se puede desvincular a participantes de forma positiva y reducir la complejidad
Gracias a estas dos propiedades, los sistemas pub/sub ganan una escalabilidad enorme. Nuevos participantes se pueden unir a la red sin mucho esfuerzo o desuscribirse sin que otros se enteren. Ese es exactamente uno de los requisitos principales de las aplicaciones IoT industriales.
Otra ventaja es la huella mínima de una pila MQTT. Con solo unos pocos kilobytes, se pueden integrar fácilmente una gran cantidad de dispositivos.
Se utilizan los llamados “temas” para que un broker sepa a quién le interesa qué datos. Un tema es una especie de carpeta donde se almacenan datos específicos. Un tema también se puede anidar para acotarlo aún más. Un ejemplo muy simple es un sensor de temperatura que desea poner a disposición sus valores de medición. Para ello, publica sus datos en el tema “temperatura”. Como una aplicación habitualmente tiene varios sensores, esto se publica de forma más específica en el tema “Temperatura/Hall_1”. Cualquier participante interesado en este valor ahora se puede suscribir al tema “Temperatura/Hall_1”, y entonces el broker le proveerá los datos nuevos cada vez que se publique algo nuevo de este tema.
Además de todas las ventajas que ofrece el MQTT, hay un gran inconveniente desde la perspectiva de las aplicaciones industriales: los datos del usuario (carga útil) del MQTT son una cadena arbitraria que no está sujeta a ninguna regla adicional con respecto al contenido o la semántica de los datos que contiene (los datos son agnósticos).
Otra ventaja es la huella mínima de una pila MQTT. Con solo unos pocos kilobytes, se pueden integrar fácilmente una gran cantidad de dispositivos.
Se utilizan los llamados “temas” para que un broker sepa a quién le interesa qué datos. Un tema es una especie de carpeta donde se almacenan datos específicos. Un tema también se puede anidar para acotarlo aún más. Un ejemplo muy simple es un sensor de temperatura que desea poner a disposición sus valores de medición. Para ello, publica sus datos en el tema “temperatura”. Como una aplicación habitualmente tiene varios sensores, esto se publica de forma más específica en el tema “Temperatura/Hall_1”. Cualquier participante interesado en este valor ahora se puede suscribir al tema “Temperatura/Hall_1”, y entonces el broker le proveerá los datos nuevos cada vez que se publique algo nuevo de este tema.
Además de todas las ventajas que ofrece el MQTT, hay un gran inconveniente desde la perspectiva de las aplicaciones industriales: los datos del usuario (carga útil) del MQTT son una cadena arbitraria que no está sujeta a ninguna regla adicional con respecto al contenido o la semántica de los datos que contiene (los datos son agnósticos).
El problema de la semántica
Cuando se transmiten datos, la pregunta que surge siempre enseguida es sobre el formato y el contenido de los datos que el receptor y el emisor de la información pueden acordar para que sea compatible. Con la introducción de los sistemas en la nube, esta cuestión se ha vuelto cada vez más grave: los proveedores de datos (en el caso de la tecnología de automatización, los equipos de la fábrica o las máquinas) casi siempre son independientes de las aplicaciones que utilizan estos datos. Esto hace que sea realmente fundamental especificar un formato fijo que todos puedan aceptar. Sin embargo, el tema es que dicho formato no existe en los sistemas en la nube y es dudoso si alguna vez existirá. Hay múltiples motivos para ello. Uno es que los proveedores de servicios en la nube tienen una gran cantidad de grupos de clientes diferentes: las soluciones en la nube la utilizan departamentos de informática, constructores de máquinas, proveedores de servicios financieros, departamentos de marketing, entre otros. Por lo tanto, la plataforma debe ser lo más flexible posible. No obstante, los formatos de datos estandarizados siempre son una limitación y, por lo tanto, los proveedores continúan conformándose con las soluciones detalladas de cada industria sobre formato de los datos.
Cuando se transmiten datos, la pregunta que surge siempre enseguida es sobre el formato y el contenido de los datos que el receptor y el emisor de la información pueden acordar para que sea compatible.
El problema para la tecnología de la automatización puede ser el siguiente: la información de la planta, en la mayoría de los casos, se presenta en formato de etiquetas del programa en un controlador. Estas etiquetas son imágenes de los valores de los procesos actuales en tipos de datos específicos como “Real”, “Int” o “Bool”. En el más sencillo de los casos, en el cual un valor de proceso se puede transmitir cíclicamente a un servidor en la nube, se deben codificar, al menos, tres tipos de información en la cadena de carga útil del MQTT:
- El valor del proceso actual de la etiqueta
- El tipo de etiqueta para que el destinatario pueda interpretarlo
En tiempos de OPC UA y especificaciones relacionadas que garantizan la interoperabilidad de diferentes dispositivos de diferentes fabricantes, la interfaz MQTT de un proveedor de servicios en la nube parece disfuncional
Además de estas tres, se puede agregar opcionalmente información adicional como código de calidad. Para simplificar la aplicación, los usuarios pueden desarrollar sus propias estructuras para representar el estado de una máquina completa. De nuevo, esto se debe codificar en la carga útil MQTT.
Como aquí no hay un estándar uniforme, en la práctica, casi cada aplicación tiene su propio formato que también necesita su propio analizador sintáctico en el momento de utilizar los datos.
Este hecho es un paso hacia atrás desde la perspectiva de la tecnología de la automatización clásica. En tiempos de OPC UA y especificaciones relacionadas que garantizan la interoperabilidad de diferentes dispositivos de diferentes fabricantes, la interfaz MQTT de un proveedor de servicios en la nube parece disfuncional. Aquí el procesamiento de datos requiere un trabajo adicional innecesario.
Una simplificación inicial y práctica es el formato JSON que provee algunas reglas de representación de datos que facilitan un poco la lectura y el análisis sintáctico de la cadena de carga útil MQTT. Aunque esto simplifica el análisis sintáctico, no lo reemplaza.
Para lograr una solución satisfactoria, los proveedores de servicios en la nube e ingenieros de automatización deben trabajar aún más de cerca y delinear juntos las interfaces futuras.
Como aquí no hay un estándar uniforme, en la práctica, casi cada aplicación tiene su propio formato que también necesita su propio analizador sintáctico en el momento de utilizar los datos.
Este hecho es un paso hacia atrás desde la perspectiva de la tecnología de la automatización clásica. En tiempos de OPC UA y especificaciones relacionadas que garantizan la interoperabilidad de diferentes dispositivos de diferentes fabricantes, la interfaz MQTT de un proveedor de servicios en la nube parece disfuncional. Aquí el procesamiento de datos requiere un trabajo adicional innecesario.
Una simplificación inicial y práctica es el formato JSON que provee algunas reglas de representación de datos que facilitan un poco la lectura y el análisis sintáctico de la cadena de carga útil MQTT. Aunque esto simplifica el análisis sintáctico, no lo reemplaza.
Para lograr una solución satisfactoria, los proveedores de servicios en la nube e ingenieros de automatización deben trabajar aún más de cerca y delinear juntos las interfaces futuras.
Los proveedores de servicios en la nube e ingenieros de automatización deben trabajar aún más de cerca y delinear juntos las interfaces futuras
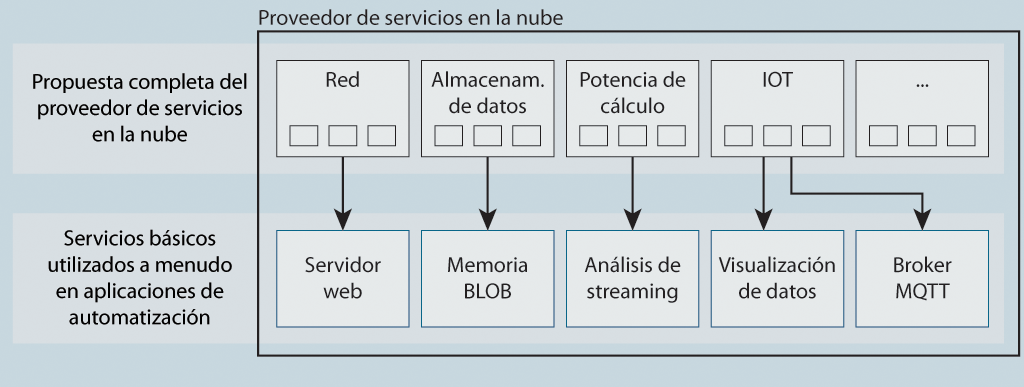 Figura 1. Servicios específicos de IIoT de proveedores de servicios en la nube
Figura 1. Servicios específicos de IIoT de proveedores de servicios en la nube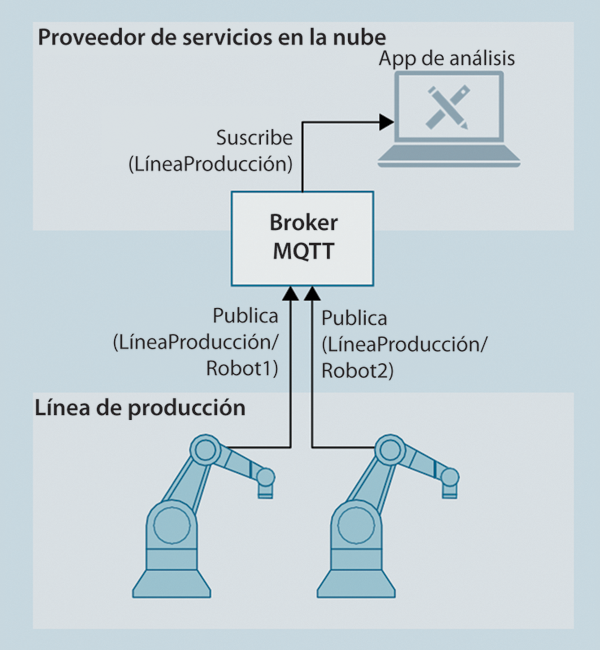 Figura 2. Concepto de publicación-suscripción de MQTT
Figura 2. Concepto de publicación-suscripción de MQTT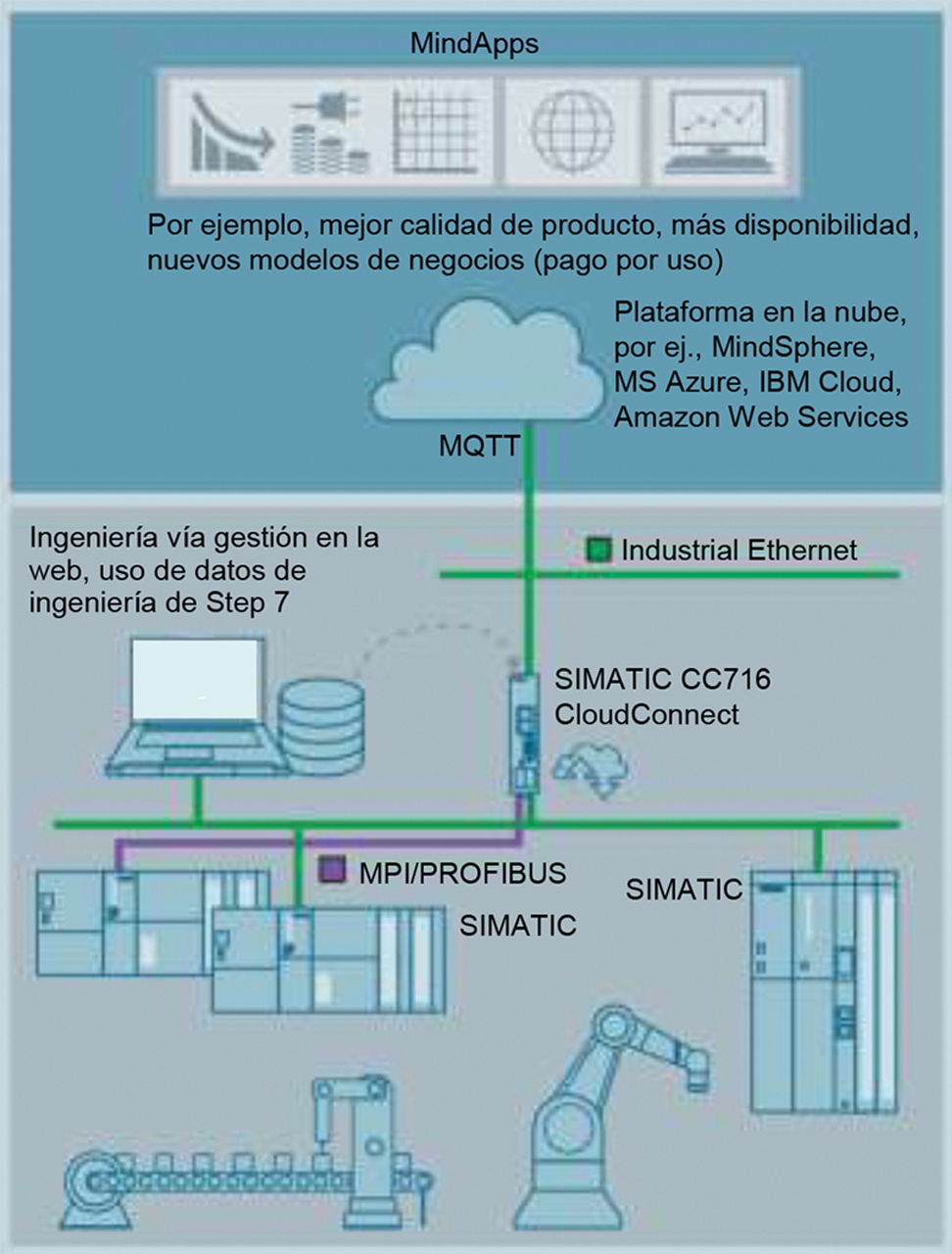 Figura 3. Configuración de sistema con gateway IIoT de Siemens, como ejemplo
Figura 3. Configuración de sistema con gateway IIoT de Siemens, como ejemplo
Los límites de las soluciones en la nube
Incluso si en la actualidad surge una aplicación tras otra, que solo fue posible mediante los enfoques en la nube, cuando se interactúa con el mundo de la automatización, aún existen límites que idealmente deberían pensarse con antelación para evitar sorpresas en el futuro.
En una tecnología de automatización clásica, el enfoque de la transmisión de datos siempre fue un intercambio rápido y cíclico de cantidades de datos relativamente pequeñas. Esto comienza con las entradas analógicas o digitales donde información muy simple como “ON” u “OFF” se transmite en el rango del microsegundo de un dígito. A esto lo siguen los buses de campo, como PROFINET o PROFIBUS, que ayudan a transmitir los datos del proceso con ciclos de transmisión seguros en solo milisegundos. Incluso los programas secuenciales de los controladores, que a veces ejecutan algoritmos y controles complejos, tienen tiempos de ciclo en el rango de los milisegundos.
En una tecnología de automatización clásica, el enfoque de la transmisión de datos siempre fue un intercambio rápido y cíclico de cantidades de datos relativamente pequeñas. Esto comienza con las entradas analógicas o digitales donde información muy simple como “ON” u “OFF” se transmite en el rango del microsegundo de un dígito. A esto lo siguen los buses de campo, como PROFINET o PROFIBUS, que ayudan a transmitir los datos del proceso con ciclos de transmisión seguros en solo milisegundos. Incluso los programas secuenciales de los controladores, que a veces ejecutan algoritmos y controles complejos, tienen tiempos de ciclo en el rango de los milisegundos.
Cuando se interactúa con el mundo de la automatización, aún existen límites que idealmente deberían pensarse con antelación para evitar sorpresas en el futuro
Sin embargo, cuando estos datos se transmiten de la red de automatización a la nube, las circunstancias cambian. Primero, los datos aumentan con información adicional como marcas de tiempo y tipos de datos. Segundo, los protocolos de comunicación cambian hacia las pilas típicas de IT TCP/IP y los mecanismos de publicación-suscripción, que generan sobrecarga de protocolo y, por ende, aumentan el volumen de los datos. Como estos protocolos tampoco garantizan tiempos de ciclo seguros o anchos de banda reservados, los tiempos efectivos necesarios para transmitir la carga útil real de un punto “A” a un punto “B” aumenta.
Esto genera cierto cuello de botella en la transición de la red de automatización a la nube que debe considerarse al discutir las posibles aplicaciones en la nube.
Esto genera cierto cuello de botella en la transición de la red de automatización a la nube que debe considerarse al discutir las posibles aplicaciones en la nube.
Esto genera cierto cuello de botella en la transición de la red de automatización a la nube que debe considerarse al discutir las posibles aplicaciones en la nube
Un ejemplo clásico para probar los límites es analizar las rutas de desplazamiento de las fresadoras en tiempo real en el servidor en la nube. El proceso de fresado es demasiado rápido como para acumular datos de alta frecuencia que deben transmitirse a la nube con la velocidad suficiente. Es exactamente por ello que muchos fabricantes enfatizan tanto en edge, es decir, en el procesamiento de datos descentralizado muy cercano al proceso mismo.
A pesar de estos límites, los casos de uso son muchos. Por ejemplo, el cálculo preciso de la vida útil de servicio de la fresadora segundo a segundo es muy factible y permite al constructor de la máquina promover el nuevo modelo de negocios tan elogiado.
A pesar de estos límites, los casos de uso son muchos. Por ejemplo, el cálculo preciso de la vida útil de servicio de la fresadora segundo a segundo es muy factible y permite al constructor de la máquina promover el nuevo modelo de negocios tan elogiado.
| Categoría de servicio en la nube | Descripción | Servicios de ejemplo |
|---|---|---|
| Almacenamiento | Almacenamiento de datos online | Backup, almacenamiento de archivos |
| Red | Servicios para la operación de una red | Servidor DNS, gateway VPN, servidor web |
| Poder de cálculo | Tercerización del poder de cálculo a máquinas virtuales | Entornos de máquinas virtuales |
| Internet de las cosas (IoT) | Networking y administración de proveedores de datos externos | Broker MQTT, análisis de streaming |
Tabla 1
Conflicto generacional: Industria 4.0 con tecnología 0.4
A pesar de la cantidad de proveedores de servicios en la nube y, por ende, de que los servicios disponibles hayan dado un enorme salto en los últimos años, en la tecnología de la automatización, tanto los ciclos de inversión, como de innovación tienden a seguir un ciclo de diez años. Los motivos son mundanos y evidentes: ante todo, los cambios se asocian con grandes costos y supuestos problemas que podrían amenazar la producción, por ende, todo el negocio.
En muchos casos, esto lleva a un conflicto concreto: luego de que la gerencia de la compañía haya decidido conectar todas las plantas y máquinas al nuevo sistema en la nube como parte de la estrategia Industria 4.0, los ingenieros de producción deben preguntarse cómo conectar su inventario de “tecnología 0.4” con equipos que tienen diez o veinte años a este sistema en la nube. Estos dispositivos claramente no tienen interfaz MQTT. En muchos casos, los datos necesarios también están ubicados en PROFIBUS o en redes seriales que —desde un punto de vista meramente físico— no pueden conectarse a redes IP.
En muchos casos, esto lleva a un conflicto concreto: luego de que la gerencia de la compañía haya decidido conectar todas las plantas y máquinas al nuevo sistema en la nube como parte de la estrategia Industria 4.0, los ingenieros de producción deben preguntarse cómo conectar su inventario de “tecnología 0.4” con equipos que tienen diez o veinte años a este sistema en la nube. Estos dispositivos claramente no tienen interfaz MQTT. En muchos casos, los datos necesarios también están ubicados en PROFIBUS o en redes seriales que —desde un punto de vista meramente físico— no pueden conectarse a redes IP.
Los dispositivos de automatización tienen su propia configuración y programación complejas que no se pueden cambiar tan fácilmente
Asimismo, los dispositivos de automatización tienen su propia configuración y programación complejas que no se pueden cambiar tan fácilmente. Estas son las complicaciones con las que deben lidiar los ingenieros. Los casos extremos —en los cuales los dispositivos se configuraron hace veinte años y cuya configuración hoy no se puede cambiar porque faltan archivos, herramientas o know-how— no son tan inusuales como uno podría suponer.
Por lo tanto, conectar una base instalada a un nuevo sistema en la nube requiere gastos que se deben considerar en cada estrategia Industrie 4.0 para calcular el valor agregado adecuadamente.
Para minimizar estos costos, muchos fabricantes ofrecen dispositivos especiales que simplifican la conexión con la nube. En la mayoría de los casos, el uso de gateways IIoT rinden, pero los dispositivos están disponibles con especificaciones muy diferentes y con un alcance funcional diverso. Por eso se recomienda una comparación técnica y pruebas de dichos gateways anticipada para que el uso posterior sea lo más sencillo y adecuado posible a la aplicación.
Por lo tanto, conectar una base instalada a un nuevo sistema en la nube requiere gastos que se deben considerar en cada estrategia Industrie 4.0 para calcular el valor agregado adecuadamente.
Para minimizar estos costos, muchos fabricantes ofrecen dispositivos especiales que simplifican la conexión con la nube. En la mayoría de los casos, el uso de gateways IIoT rinden, pero los dispositivos están disponibles con especificaciones muy diferentes y con un alcance funcional diverso. Por eso se recomienda una comparación técnica y pruebas de dichos gateways anticipada para que el uso posterior sea lo más sencillo y adecuado posible a la aplicación.
Selección del gateway industrial IoT adecuado
Cuando los dispositivos o las máquinas no tienen una interfaz MQTT nativa y deben conectarse a un servicio en la nube, se necesita un gateway industrial IoT.
El gateway asume las siguientes funciones básicas:
El gateway asume las siguientes funciones básicas:
- Recolección de datos de la red de automatización
- Filtro de los contenidos y conversión de los formatos de datos
- Transmisión de los datos a la interfaz en la nube
Los gateways industriales IoT están disponibles en diferentes versiones, de diferentes proveedores. Por ende, también hay una gran variedad, incluso para las funciones más básicas.
A continuación, algunos aspectos que se debe considerar a la hora de seleccionar el gateway industrial IoT adecuado.
A continuación, algunos aspectos que se debe considerar a la hora de seleccionar el gateway industrial IoT adecuado.
¿Es un producto o un sandbox?
Por un lado, se debe distinguir claramente entre productos industriales y sistemas abiertos sandbox (entornos de prueba). Un gateway industrial IoT viene en una carcasa con opciones de montaje diseñadas específicamente para los gabinetes de control y las condiciones ambientales correspondientes. Las soluciones sandbox son habitualmente tableros tipo Raspberry Pi alojados en una carcasa compatible. Dichas soluciones poseen un entorno de desarrollo que permite desarrollar de forma flexible sus propios programas o ejecutarse en aplicaciones de fuente abierta. Por otro lado, los dispositivos industriales poseen un alcance funcional definido que se configura mediante opciones de configuración especialmente diseñadas (en general, un servidor web).
Según la aplicación, una de las soluciones será la mejor opción. Si el enfoque es específicamente implementar la aplicación según un esquema fijo con el menor esfuerzo posible, un producto industrial es una buena opción.
Según la aplicación, una de las soluciones será la mejor opción. Si el enfoque es específicamente implementar la aplicación según un esquema fijo con el menor esfuerzo posible, un producto industrial es una buena opción.
Un gateway industrial IoT viene en una carcasa con opciones de montaje diseñadas específicamente para los gabinetes de control y las condiciones ambientales correspondientes
¿Qué interfaces ofrece a nivel de campo?
El tipo de dispositivos de campo que se pueden conectar, como controladores, motores o sensores, es otro de los criterios principales. Aquí, el primer paso sería crear una lista de todos los dispositivos desde los cuales se enviarán los datos a la nube.
Cada uno de estos dispositivos soporta protocolos especiales como Modbus, S7 o PROFIBUS. Por lo tanto, el gateway industrial IoT debería admitir inherentemente estos protocolos para que no deban hacerse cambios a los dispositivos de campo.
Cada uno de estos dispositivos soporta protocolos especiales como Modbus, S7 o PROFIBUS. Por lo tanto, el gateway industrial IoT debería admitir inherentemente estos protocolos para que no deban hacerse cambios a los dispositivos de campo.
¿La interfaz en la nube es lo suficientemente flexible?
Una vez descifradas las opciones de conectividad de los dispositivos de campo, se debe dirigir la atención hacia los proveedores de servicios en la nube admitidos. Aunque la mayoría de los proveedores de servicios en la nube admiten el estándar MQTT, podría haber algunas restricciones específicas. En algunas soluciones, los nombres de los temas y los formatos son fijos. El gateway industrial IoT debería poder manejar esto, por ende, el usuario debería asegurarse de que los sistemas en la nube admitidos se mencionen explícitamente en las características del producto o que el dispositivo sea lo suficientemente flexible como para ajustarse mediante su configuración.
Asimismo, los requisitos adicionales son muy importantes para muchas aplicaciones. Además del nuevo servidor en la nube, el MES (‘sistema de ejecución de manufactura’, por sus siglas en inglés) existente a menudo continúa ejecutándose en paralelo. Aquí también podrían requerirse nuevos valores de proceso. Por lo tanto, la gateway industrial IoT debería poder proveer adicionalmente datos al MES, por ejemplo, vía interfaz OPC UA.
Asimismo, los requisitos adicionales son muy importantes para muchas aplicaciones. Además del nuevo servidor en la nube, el MES (‘sistema de ejecución de manufactura’, por sus siglas en inglés) existente a menudo continúa ejecutándose en paralelo. Aquí también podrían requerirse nuevos valores de proceso. Por lo tanto, la gateway industrial IoT debería poder proveer adicionalmente datos al MES, por ejemplo, vía interfaz OPC UA.
La pregunta sobre los límites de la configuración de los datos necesarios es quizás una de las más frecuentes que queda sin respuesta por mucho tiempo en el contexto de la creación de la estrategia Industria 4.0
¿Cuántos dispositivos y puntos de datos se necesitan realmente?
La pregunta sobre los límites de la configuración de los datos necesarios es quizás una de las más frecuentes que queda sin respuesta por mucho tiempo en el contexto de la creación de la estrategia Industria 4.0. Una pregunta directa en este contexto sería, por ejemplo, “¿cuántos valores de proceso se necesitan desde una celda de producción?”. Esa pregunta debe responderse al principio, si no, la implementación podría llevar a un callejón sin salida. Por eso también debe prestarse atención a la información sobre los límites de la configuración (cuántos puntos de datos admite cada dispositivo) de las especificaciones técnicas de la gateway industrial IoT. Si no hay información sobre esto en el producto, se debe asumir que el fabricante no realizó pruebas. Eso representaría un mayor riesgo para la implementación que debería descartarse desde el principio.
Otros aspectos a tener en cuenta
- Redes individuales. Por motivos de seguridad, debe garantizarse que el gateway pueda trabajar en dos subredes totalmente diferentes (una para la nube, una para la red de automatización), y el que un enrutamiento entre ellas no sea posible.
- Soporte de entradas/salidas digitales o analógicas. En aplicaciones industriales, las E/S se necesitan constantemente para influenciar el proceso cuando sea necesario. Un ejemplo muy simple sería un interruptor para una desconexión brusca de la transmisión de datos a la nube porque se ha detectado un riesgo.
- Reemplazo simple de los dispositivos. Se debería poder reemplazar un dispositivo de forma sencilla para no demorar innecesariamente el proceso de producción. Una opción razonable que debería considerarse es la transferencia de la configuración del dispositivo vía USB al nuevo dispositivo.
- Sincronización temporal. Como todos los valores del proceso deben tener una marca de tiempo, el gateway debe poder sincronizar el tiempo mediante un servidor. Configurar el tiempo en un dispositivo manualmente es útil para la puesta en marcha, pero no es suficiente para un proceso continuo. Se debe ofrecer una sincronización automática (por ejemplo, vía NTP) para evitar la distorsión de los valores temporales en caso de una falla en el suministro de energía.
Por Andrés Gorenberg, Siemens
Autor:
Todas las publicaciones de:
Publicado en:
Número:
Mes:
Año: